GPT-Crawler一键爬虫构建GPTs知识库
本文Node.js和GPT-Crawler下载链接都已放于文末
能够爬取网站数据,构建GPTs的知识库,项目依赖node.js环境,接下来我们按步骤来安装,非常简单
安装node.js
下载20.10.0版本即可,下载后一路默认安装
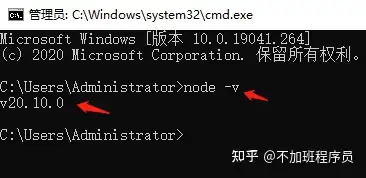
安装完成后在命令行输入node -v,显示版本则安装成功
安装GPT-Crawler
项目地址:github.com/BuilderIO/gp
这个项目能爬取网站数据,生成用于创建GPTs的知识库文件
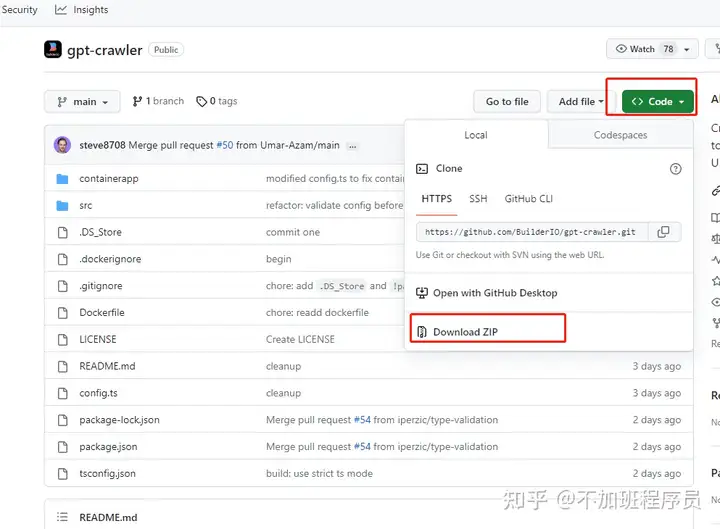
打开项目地址后,点击【Code】,下载压缩文件,保存到电脑本地解压
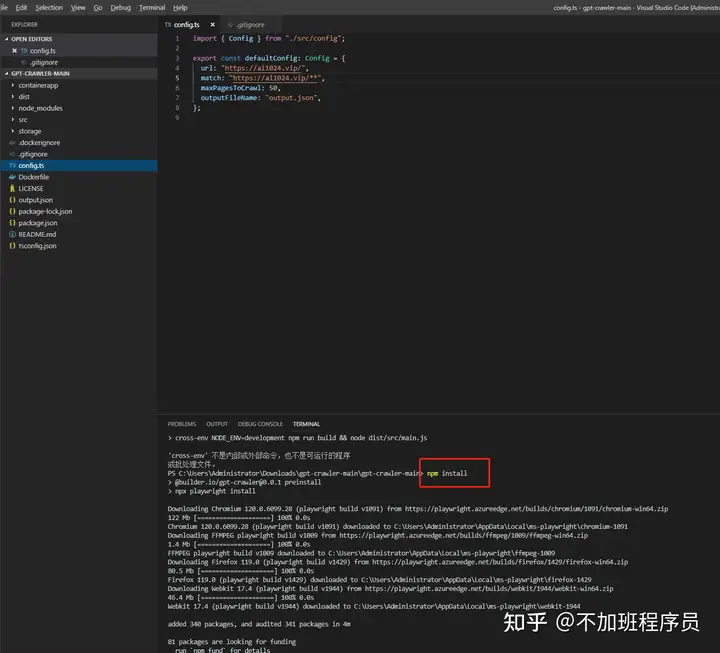
用VSCode编码工具打开,切换到项目目录,输入npm install,把项目依赖包进行安装
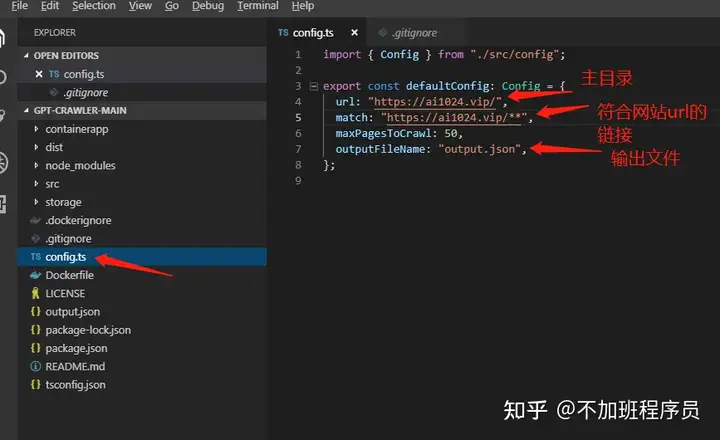
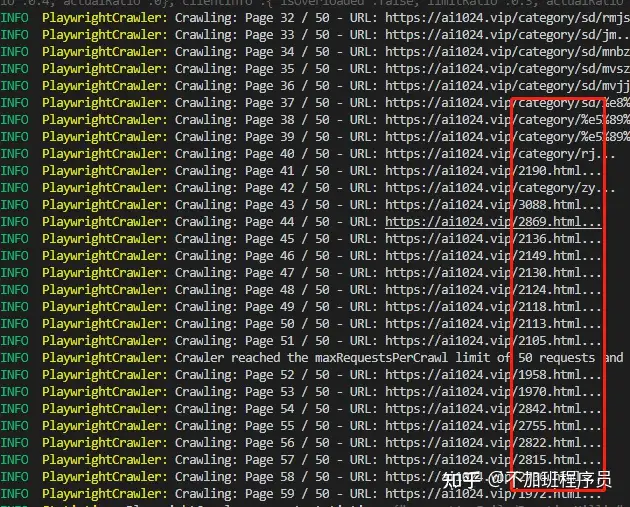
在config.ts进行简单配置,输入一个指定的网站
可以看到只要匹配到URL的网址链接,都已经被爬到了
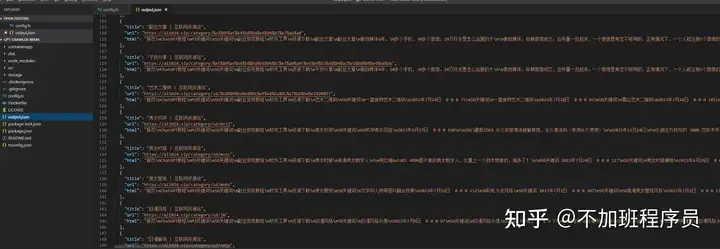
输出文件为output.json,点开看一下,很完美
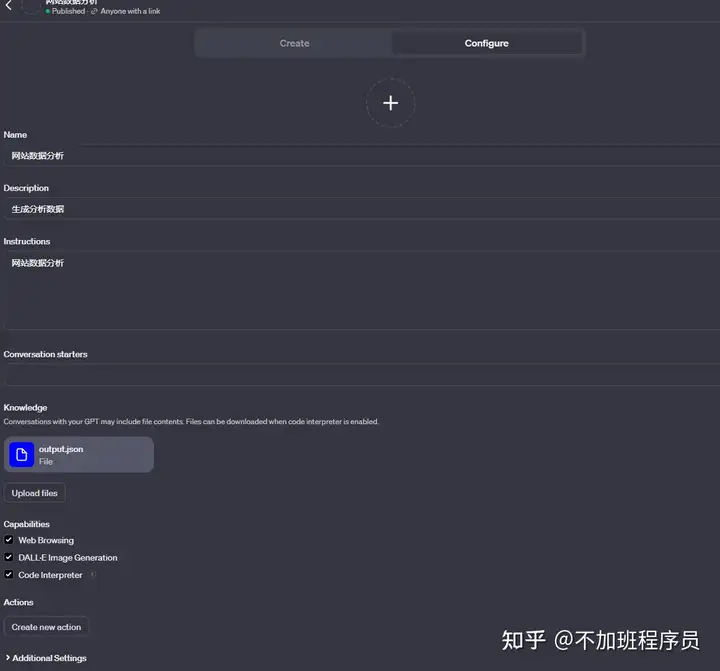
然后创建GPTs,传入output.json文件
我就简单问一下爬取的数据中知识库的内容,GPT给我已经描述出来了